Abstract
LiDAR-based 3D object detectors have achieved unprecedented speed and accuracy in autonomous driving applications. However, similar to other neural networks, they are often biased toward high-confidence predictions or return detections where no real object is present. These types of detections can lead to a less reliable environment perception, severely affecting the functionality and safety of autonomous vehicles.
We address this problem by proposing LS-VOS, a framework for identifying outliers in 3D object detections. Our approach builds on the idea of Virtual Outlier Synthesis (VOS), which incorporates outlier knowledge during training, enabling the model to learn more compact decision boundaries. In particular, we propose a new synthesis approach that relies on the latent space of an auto-encoder network to generate outlier features with a parametrizable degree of similarity to in-distribution features. In extensive experiments, we show that our approach improves the outlier detection capabilities of a state-of-the-art object detector while maintaining high 3D object detection performance.
Method
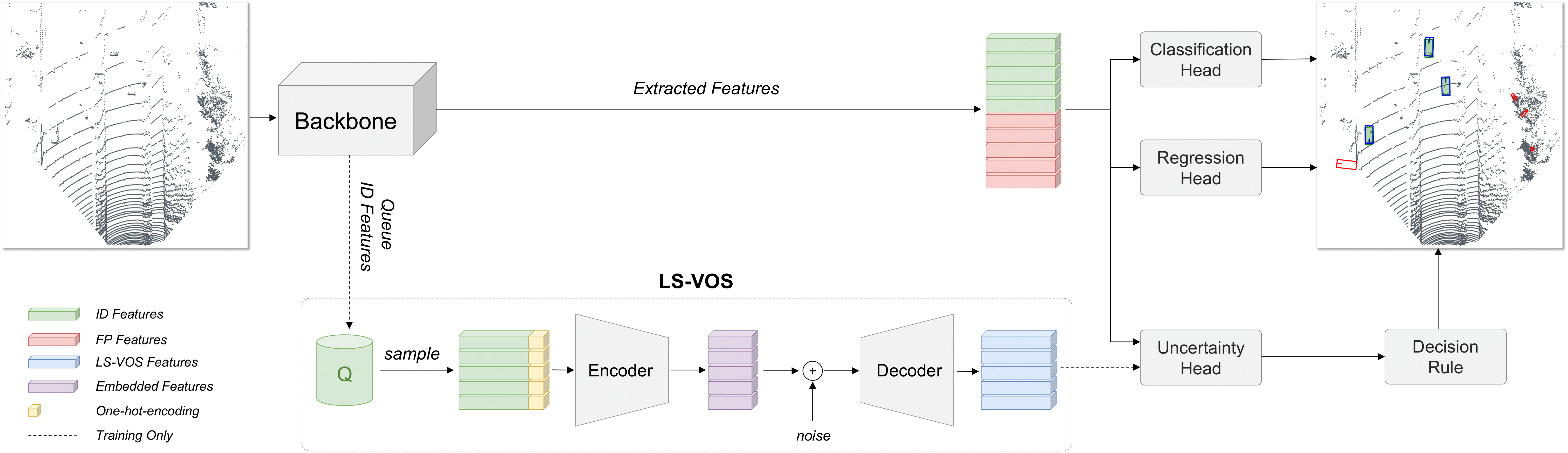
Overview of the proposed LS-VOS framework. During training, the backbone of a 3D object detector extracts features from the input point cloud. Based on the IoU with the ground truth bounding boxes, features are divided into in-distribution (ID) and false positives (FP). The ID features, concatenated with the one-hot-encoded predicted class, are saved at each training step in a queue Q. To synthesize virtual outliers, ID features are randomly sampled from Q and an encoder (E) is used to embed them. Random noise is added to the embedded features which are then reconstructed using a decoder (D). These reconstructed features (virtual outliers) are used together with ID and FP to train the uncertainty head, which returns high scores for OOD objects and low scores for ID objects. In the detection plot, we use the color green for ground truth boxes and blue for predictions. We use red to highlight the predicted boxes classified as OOD.
Results
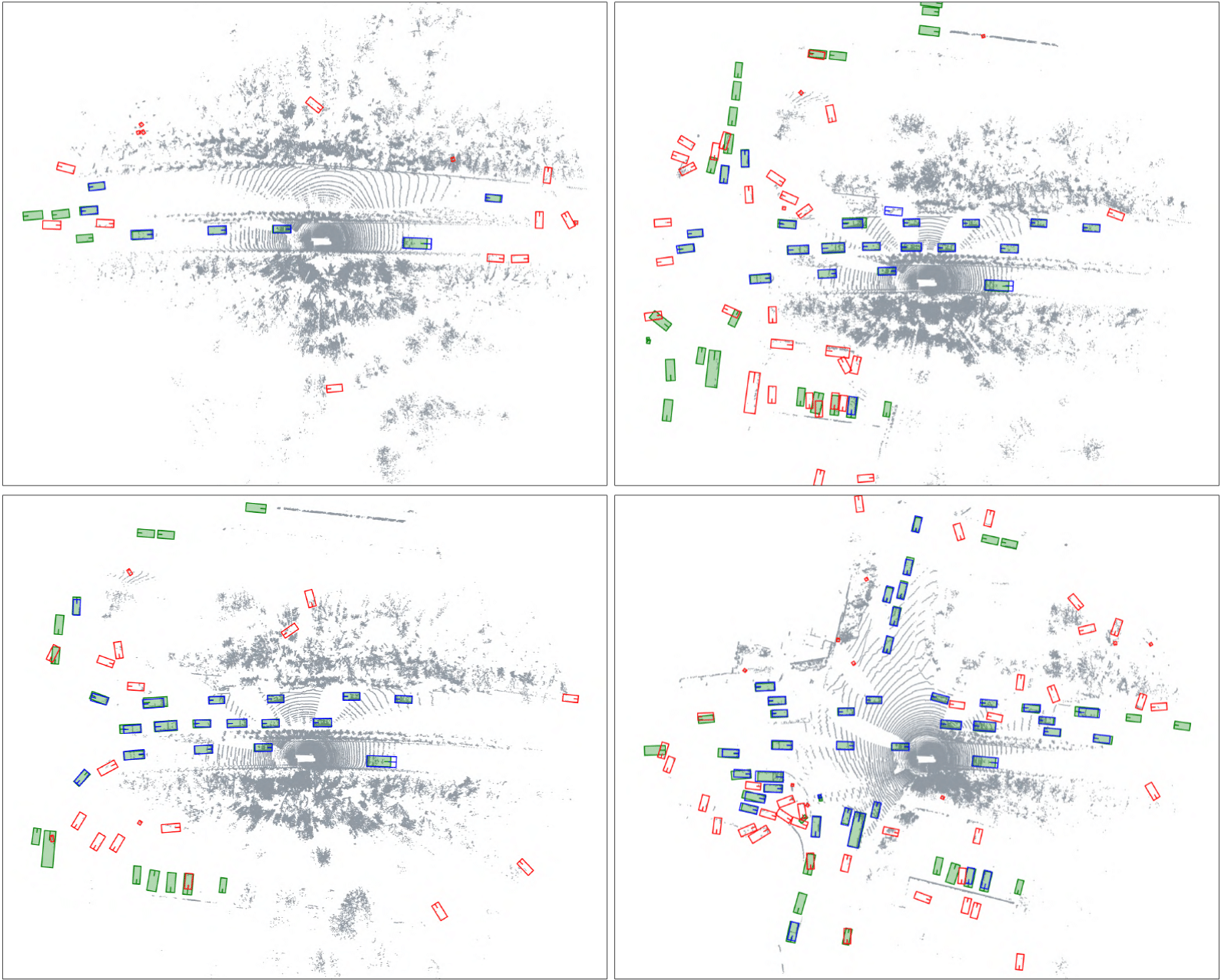
Qualitative results of PV-RCNN++ trained with the proposed LS-VOS framework. All four scenes are from the Waymo Open Dataset validation set. In green, we report the ground truth bounding boxes, and in blue the predicted bounding boxes. In red, we highlight the detections classified as OOD using the decision rule with threshold \(\tau\) chosen at \(95\%\) true positive rate.